在机器学习和智能算法大热的时代,不甘于寂寞的前端同学们也开始涉足智能领域,各种sketch2code层出不穷,那么让我们从基础开始一步步揭开智能算法的神秘面纱。
分类
在机器学习领域,一个实际场景的问题往往会被划分成回归、分类、聚类问题,其中又属分类问题最为常见。今天我们就来了解一下什么是分类、并且怎么解决一个分类问题。
定义
first of all.我们先来学习一下什么是分类。
“帝釐下土,方設居方,別生分類,作《汩作》。”
《書‧舜典》附亡《書》序
意指将无序的事物按照种类、等级、特点或性质划分成一组相似的物品过程。人们从这样的过程中不断总结归纳形成了一门一同学科,分类学。分即鉴定、描述和命名,类即归类,按一定秩序排列类群,形成系统演化。例如生物学中的界、门、纲、目、科、属、种7个分类等级便是分类学在生物中的运用。
相似性
大家可以思考一下,按照直觉逻辑,你们的分类依据是什么?没错,物与物之间相似性。相似的东西我们会归在一起,南辕北辙的东西一定不在一个类别。那么相似性应该怎么量化呢。这里就是我们的重点了。
距离
在涛涛历史长河中,人类的智慧在于总是能够将不同的经验总结抽样化归到另一个场景发光发热。物理学中,我们通过估计计算距离来对两个物体位置进行描述,数学中,我们通过距离这个计算函数来描述空间某些元素是否相互接近或者原理。那么如果我们能够将一个物品的种类、等级、特点通过空间中的一个元素来表示,元素之间的相似性是否就能够通过空间距离被量化出来了呢?
欧几里得距离
让我们回到公元前三世纪,伟大的数学家、几何学之父欧几里得通过证明毕达哥拉斯定理从而告诉了世界平面中任意两点的距离应该如何计算,史称欧几里得距离。后人成功论证了他在二维、三位空间距离的计算法适用于任何有限维度。


让我们回到刚刚的问题上来,空间中的两个元素之间的相似性能够被空间距离量化么?
这里以data-mining中的例子来说明。以亚马逊中不同用户对两本书的评价为例。其中评价等级为0-5颗星。

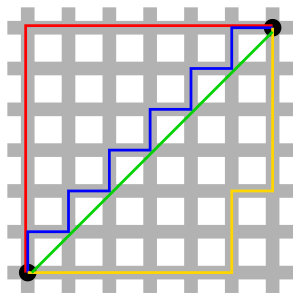
由于是两本书的评价,我们可以将其置于二维空间中,以Snow Crash为横轴,Girl with the Dragon Tattoo为纵轴,可以绘制出如下坐标系

计算欧几里得距离我们得到
D(Jim-Bill) = 2
D(Amy-Bill) = 3
D(Jim-Amy) = sqrt(17)
根据计算可以发现 D(Jim-Bill) < D(Amy-Bill) < D(Jim-Amy)
因此我们认为Jim和Bill的阅读口味相似度较高,可以把他们划分到一个类别中。
曼哈顿距离
在扩展到n维空间时(即本例中对n本书籍的评分),欧几里得距离的计算会涉及海量的平方和开方运算,数量量大的时候计算速度明细下降。如果我们简化一下计算公式来近似表示距离的度量。由于勾股定理斜边长度仅与领边长度相关,那么距离的测量我们可以近似表示成

这便是十九世纪由闵可夫斯基提出的曼哈顿距离,又称街区距离,也是目前我们地图路径规划的理论基础。
皮尔逊系数
按照上面书籍评分的例子思考一下这个问题, 林子大了什么鸟都有,我们有三个风格迥然相异的用户。
- Bill没有打出极端的分数,都在2至4分之间;
- Jordyn似乎喜欢所有的乐队,打分都在4至5之间;
- Hailey是一个有趣的人,他的分数不是1就是4。
那么这些用户间还能够直接通过我们的5分标准坐标轴计算距离来判别相似性么?Hailey打的4分对应与Jordyn的4分还是5分呢, 应该更接近5分吧。我们会发现当我们的变量量纲标准不一致的时候,仅仅用距离去计算相似性的方法效果好像就不好了。我们必须要去消除量纲的影响。
Z-score标准化
我们希望所有值能够落到一个标准的量化范围内。借助统计学中的经验,用z-score来计算标准分数

一个统计值减去均值再除以标准差,这样他的取值范围就落在了[-1, 1]之间,并且z的均值为0,标准差为1,无论量纲如何变化,都能被标准化到范围区间。
我们将标准化后的特征量纲再代入到之前的欧氏距离计算中。
设有两个向量 和
维度相同为n.
已知X与Y均作了标准化处理,因此均值ux,uy为0,标准差αx, αy为1。有
当n趋近于无穷时 因此可得
回顾一下欧式距离的计算公式,为了简化运算,这里我们不做开方处理。
将上述结论带入欧式距离公式
这里的
便是我们的皮尔逊系数了。可以发现皮尔逊系数其实就是标准化后的向量点积。让我们再按直觉逻辑算一下,距离越大,皮尔逊系数越小,距离越小皮尔逊系数越大。恩没问题。
余弦相似性
余弦相似给出了另一个角度的相似性解释。余弦相似并不关注数值的度量而是关注维度的度量,根据空间向量夹角来区分两个物体方向性的差异。余弦相似由于对数值不敏感,所以也
会面临之前评分标准的问题,因此我们会对余弦相似进行修正。对用户的评分标准进行减去均值的运算来平衡尺度差异。

我们将标准化后的向量代入余弦公式
惊奇的发现和欧几里得距离以及皮尔逊公式形式高度的一致,殊途同归了。
knn
knn 又称k临近算法,在相似性计算的基础上,我们会筛选出最相似的k组记录并根据记录的分类结果进行投票。选举出最终的分类,
实战
原理我们都懂了,快干起来吧。
这里我们实现了一个从后台字段到前端渲染器匹配的一个场景。在我们的可视化系统中会将每一个后台接口的字段匹配到前端的一个组件渲染器上(最通用的例子就是列表页每一列的字段会对应一个列渲染器)。
特征工程
这里的特征工程非常简单,我们先将系统存储的所有有台字段进行分词并去重得到一张特征表

根据系统中的记录的后台关键词,将关键词映射成shape为[1, 特征表长度]的一个稀疏矩阵。根据特征表,若后台字段包含特征表中的关键字,则该位置为1,否则置为0。
tensorflow接入
本次实践基于@tensorflow/tfjs-model/knn-classifier。knn-classifier分类器源码中两个关键流程如下所示
similarities
这个函数便是我们上面老生常谈的相似性计算
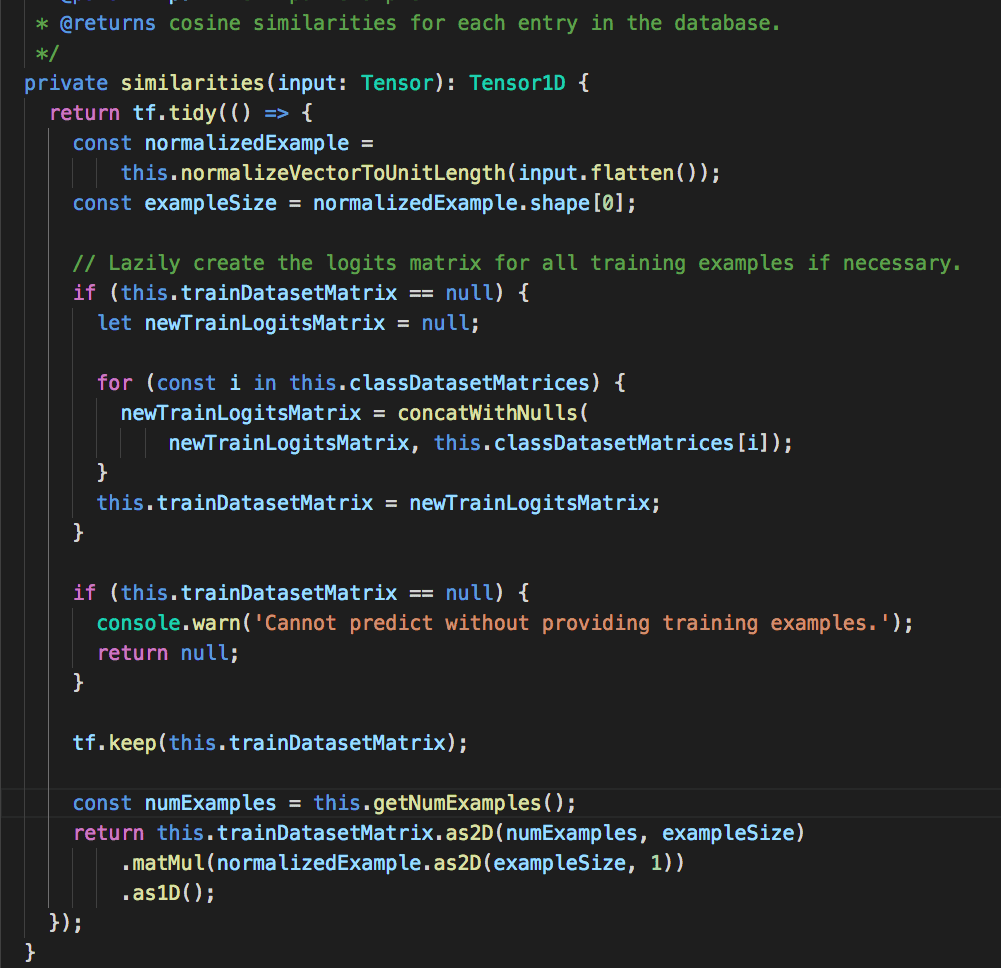
逻辑其实也很简单先对,输入向量进行标准化,然后和训练集(在输入训练集时已被标准化)进行矩阵乘运算。这里的矩阵乘积其实对应的便是我们上文中提到的标准化后的皮尔逊定理和余弦角公式的分子。由于标准化后分母可以看成是一个常量,因此仅计算分子便可决定相似度。函数会返回一个一维向量, 或者我们可以看成是一个一维数组,数组每项的索引与训练集中的向量索引对应, 值代表着该训练向量与输入向量的相似得分(正相关)。
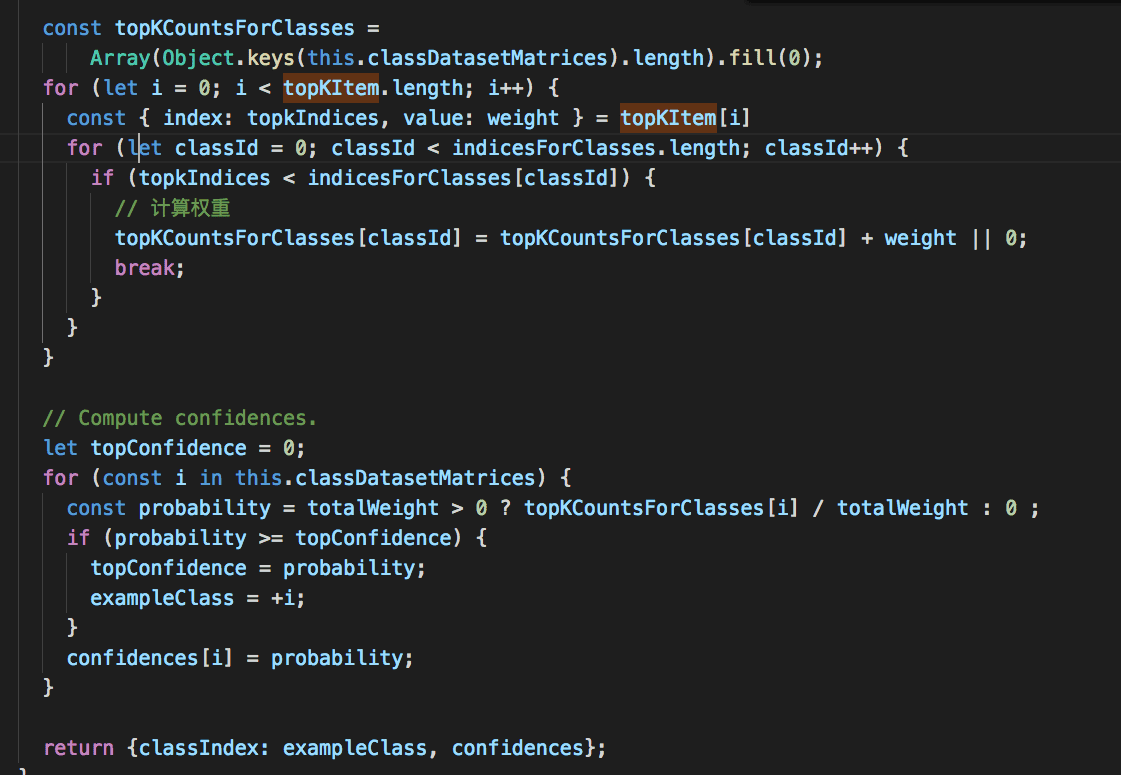
topK && calculateTopClass
这两个函数真正意义上完成了knn的逻辑,完成了根据相似性排序并投票选举最终分类的过程。
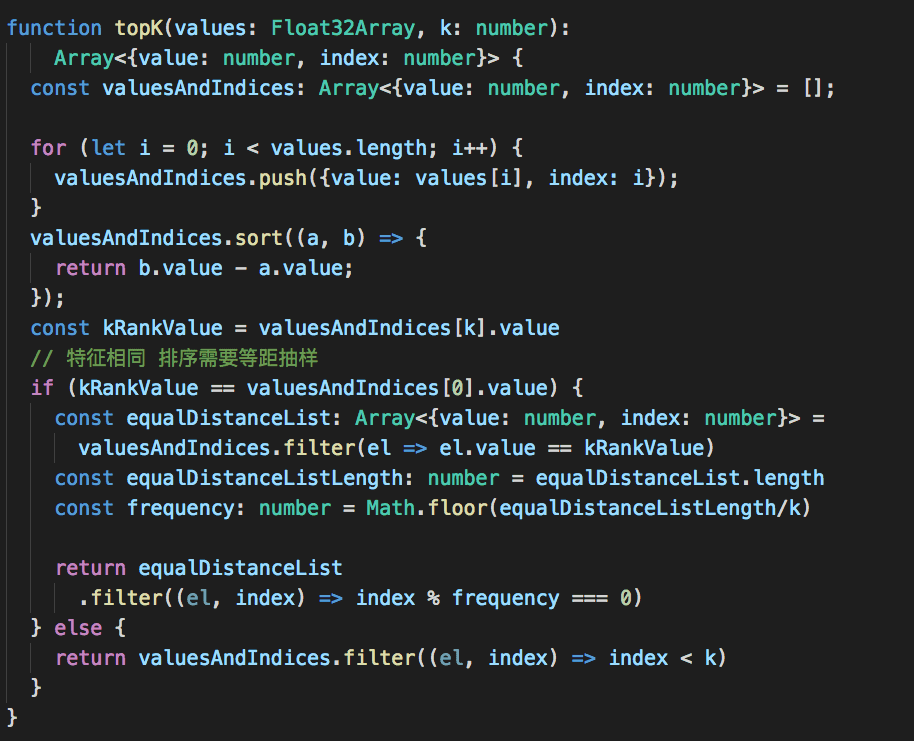
我们先来看下topK的源码

将similarities计算所得的一维向量中每项的值和索引保存下来,根据值(相似度得分)排序得到降序数组,并取前k项返回。
接下来返回的k项结果将会传入calculateTopClass进行投票选举,根据数据项中的索引找到k个数据项分别对应的类别标签分组,取标签分组比例最高的类别标签作为输入向量的最终分类。

实践
等相似得分下分桶抽样优化
在我们的实践场景中,由于特征向量非常稀疏的特性,发现常常会有等相似得分的情况,而knn-classifier源码中等相似得分情况下,默认是按照类别分组依次排序的。
举个例子,训练集中分类1有100个向量,分类2有200个向量。在所有训练集向量和输入向量等相似性得分的情况下,输出的排序为
|
|
此时只要k值小于100则分类结果一定为1。与事实相悖,等相似的情况下分类2的占比高于分类1, 结果为分类2的可能性更大。
基于这样的问题,针对等相似等分情况进行了分桶抽样优化,使得输出的排序变为
|
|
如图
投票权重策略优化优化
knn-classifier的源码没有投票权重策略,在遇到对于不同相似得分k项均等同视之,在特征稀疏的情况下会出现以下的问题。
假设k=3, 且三项的相似得分和记录为
|
|
时,分类结果为2。而实际的情况则是第一项更贴近我们的输入向量。因此引入了简易的相似性得分权重策略。如图。
验证
我们需要一个验证function来衡量我们的分类器表现,通过将总数据集拆分成测试集和训练集,通过分类结果和测试集本身标签对比来作为分类器的评价,个人提供了三种测试集抽样方式:随机抽样、等距抽样和十折验证,这里推荐使用十折验证法
十折验证法
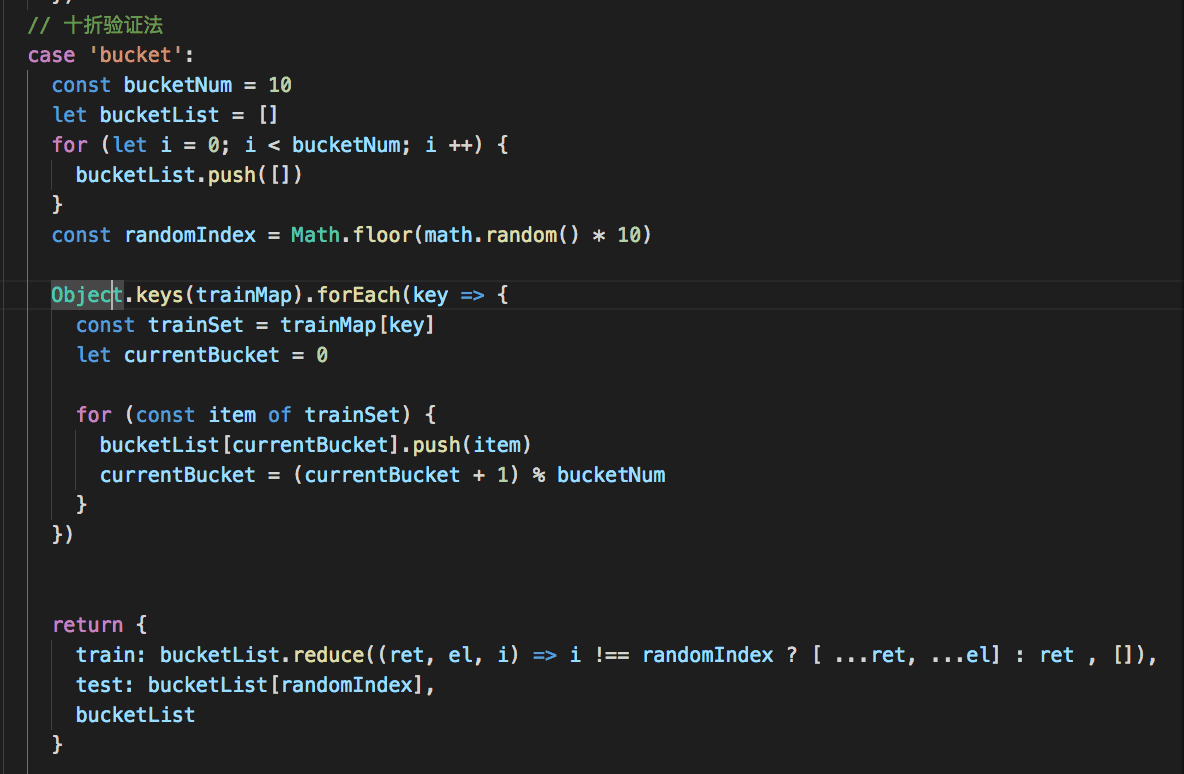
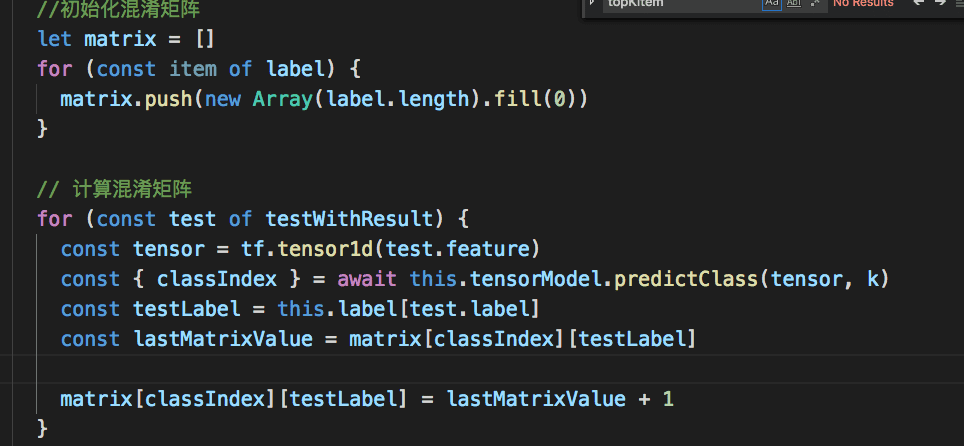
计算混淆矩阵和表现系数
通过计算混淆矩阵和kappa系数作为分类器评价指标。由于这些资料网上很全,就不多赘述了。(其实tensorflow自己就提供了confusionMatrix的计算api,写完才发现)
![]()
关于代码
所有代码已经开源至: 传送门